Robots.txt is een tekstbestand dat in de hoofdmap van een website staat. Als websites een robots.txt hebben, kun je die vinden door naar www.voorbeeldwebsite.nl/robots.txt te gaan. Met dit bestand kun je aangeven welke pagina’s van je website zoekmachines wel en niet mogen crawlen (= bezoeken). Als er niets in de robots.txt staat, betekent dat dat zoekmachines alle pagina’s mogen crawlen. Als je wilt dat ze bepaalde pagina’s niet crawlen, kun je dat aangeven met Disallow: pagina.
Werken robots.txt voor alle zoekmachines?
Dat kun je zelf bepalen. In je robots.txt moet je aangeven voor welke zoekmachines je de regels wilt laten gelden. Dat doe je door het volgende te typen:
User-agent: Googlebot
Deze geldt uiteraard voor Google. Voor Bing gebruik je bingbot en voor Yahoo slurp. Wil je alle zoekmachines meenemen, dan zet je een * achter user-agent. Dat ziet er zo uit:
User-agent: *
Waarom pagina’s uitsluiten voor zoekmachines?
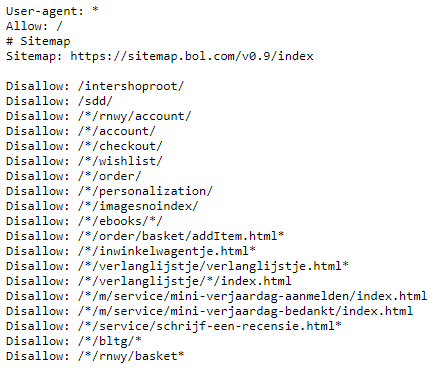
Zoekmachines kunnen maar een bepaald aantal pagina’s crawlen per website. Dit wordt het crawlbudget genoemd. Je wilt natuurlijk dat zoekmachines alleen de belangrijkste pagina’s van je website crawlen. Als je bijvoorbeeld een webshop hebt, wil je niet dat Google filterpagina’s of de winkelmandje pagina’s crawlt. Je productpagina’s zijn de pagina’s waarop je gevonden wilt worden. Om deze reden kun je de robots.txt inzetten om ervoor te zorgen dat de niet belangrijke pagina’s niet worden gecrawld. Als voorbeeld is hier een stukje van de robots.txt van Bol.com:
Met deze disallows zegt Bol.com tegen alle zoekmachines dat ze alle pagina’s inclusief de sitemap mogen crawlen, maar onder andere niet de pagina’s ‘account’, ‘checkout’, ‘verlanglijstje’ en ‘in winkelwagentje’.
Hoe maak je een robots.txt bestand?
Om een robots.txt bestand te maken heb je een teksteditor nodig. Gebruik geen tekstverwerker (zoals Word of Google Docs), want die kunnen het bestand in eigen opmaak opslaan, waardoor het bestand niet meer goed leesbaar is voor zoekmachines. Je kunt een robots.txt maken in bijvoorbeeld Kladblok (zit standaard op Windows) of in Notepad++ (uitgebreidere versie van Kladblok, gratis te downloaden).
De belangrijkste regels wat betreft het schrijven van een robots.txt:
- Elke website mag maar één robots.txt bevatten
- De robots.txt moet direct na het hoofddomein van de website komen. Dus wel: www.website.com/robots.txt. Niet: www.website.com/pagina/robots.txt. Weet je niet hoe je een robots.txt moet toevoegen of heb je de rechten niet? Neem dan contact op met je webhostingprovider.
- Een robots.txt bestand bestaat uit één of meerdere groepen
- Elke groep bestaat uit regels met instructies (één instructie per regel)
- Een groep geeft de volgende informatie:
- Voor wie de instructie bedoeld is (de user-agent)
- Welke pagina’s de user-agent wel kan openen (allow)
- Welke pagina’s de user-agent niet kan openen (disallow)
- Bovenaan de groep kun je door middel van # aan het begin van de regel uitleggen wat de user-agent is of wat de instructie precies doet. Bekijk hieronder een stukje van de robots.txt van Wikipedia. Deze specifieke robots mogen de hele website niet crawlen.
Robots.txt voor WordPress
Heb je een WordPress website? Lucky you! Als je de Yoast plugin hebt gedownload (wat altijd een goed idee is), hoef je niet meer eerst langs je webhostingprovider om de robots.txt aan te maken of aan te passen. Deze plugin genereert automatisch een robots.txt voor je website. Deze ziet er standaard zo uit:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Als je het bestand wilt aanpassen, ga je in WordPress naar SEO –> Extra (in sommige versies van WordPress heet dit ‘Tools’) –> bestandsbewerker.
Klik vervolgens op: Maak robots.txt bestand aan.
Vervolgens bewerk je het bestand en sla je het op.
Wanneer gebruik je Allow in het robots.txt bestand?
Voor pagina’s waar geen Disallow voor gebruikt wordt, geldt automatisch dat zoekmachines de pagina mogen crawlen. Waarvoor gebruik je dan nog Allow? Dat gebruik je als robots de meeste pagina’s van een bepaald subdomein van je pagina niet mogen crawlen, maar één of enkele pagina’s of bestanden daarin wel. Dan ziet het er als volgt uit:
User-agent: *
Disallow: /subdomein/
Allow: /subdomein/pagina
Beperkingen van robots.txt
Let op: Als een pagina wordt geblokkeerd in de robots.txt, betekent dat niet perse dat die pagina niet meer wordt vertoond in de zoekresultaten. Als er vanaf een link nog wel wordt verwezen naar die pagina, kan het zijn dat die pagina nog gewoon wordt vertoond. Er staat dan alleen geen website-informatie bij. Als je wilt dat een pagina helemaal niet wordt weergegeven in de zoekresultaten, kun je een no-index gebruiken.